
When dealing with large files, hashing is a nice way how to reduce the file into a small fingerprint – a short string that somehow represents the contents of the entire file.
Hashing has multiple uses, for example it gives us a nice integrity check when transfering the file. It is also used in most digital signatures – as signing is usually slower than hashing, you first hash the file, and then sign the fingerprint.
Most of the hash functions have the property that even if just one byte of the file changes, we have to process the entire file again in order to find the new hash value.
In this task we investigate some options how to design a hash function that would allow us to update the hash value quickly after we make a change to the hashed file. We will use the following approach:
 ⊕ Hn), or we can add the individual hashes as
numbers, computing modulo 2m (so the final hash would be A = (H1 + H2 +
⊕ Hn), or we can add the individual hashes as
numbers, computing modulo 2m (so the final hash would be A = (H1 + H2 + 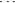 + Hn) mod 2m).
We will call the two approaches XOR-HASH and ADD-HASH, respectively.
+ Hn) mod 2m).
We will call the two approaches XOR-HASH and ADD-HASH, respectively.Problem specification
Invert the hash functions described in the problem statement. That is, both for XOR-HASH and for ADD-HASH you should provide a file with a prescribed hash value.
Note that while there are known attacks to find collisions in MD5, so far it is not known how to invert this function efficiently.
Input specification
You are given a sample implementation of the MD5 hash function along with a testing program and example output files for a team with TIS 12345678901234567890.
Output specification
As the output for the easy data set H1, output the hex dump of a file which has n = 256 blocks (i.e., its size is 65536 bytes). After calculating the XOR-HASH of this file, the hexadecimal notation of the result must be 00000 00000 00XXX XXXXX XXXXX XXXXX XX, where the string of 20 Xs should be replaced by your TIS.
As the output for the hard data set H2, output the hex dump of a file which has n = 128 blocks (i.e., its size is 32768 bytes). The ADD-HASH of this file must be 00000 00000 00XXX XXXXX XXXXX XXXXX XX, where the string of 20 Xs should be replaced by your TIS.
The hex dump of a B-byte file should consist of B pairs of hexadecimal digits separated by any whitespace. For example, if the first three bytes of your file have ASCII values 97, 32, 10, the hex dump of this file would start “61 20 0a”.
Instead of the provided MD5 implementation, you should be able to use any software that computes MD5 hashes of files. If your operating system contains the od application (octal dump, a part of GNU coreutils), you can easily create the hex dump of a file using the command od -v -A n -t x1.